pythonにおいて、ファイルを比較し、差分や一致箇所を抽出する方法を紹介します。
本記事では、ファイル比較を行う方法として、pythonの標準モジュールである「difflib」モジュールを用いた方法を紹介します。
この記事で分かること
- 「difflib」モジュールとは
- Differクラスでファイルの比較結果を出力する方法
- 【補足】Differクラスの出力結果から、差分、一致箇所を抽出する方法
- HtmlDiffクラスでファイルの比較結果を出力する方法
- SequenceMatcherクラスの使用例
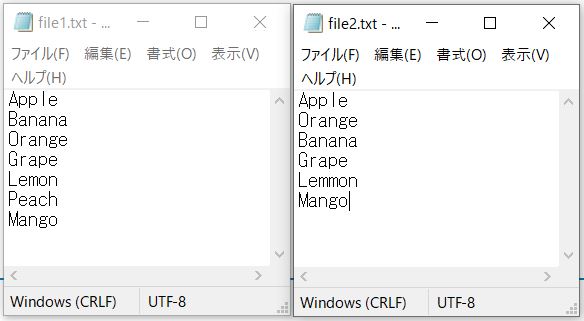
なお、本記事で紹介するサンプルコードでは、下記2つのファイルを比較しています。
データの並び順変更やスぺスミスがあります。
スポンサーリンク
「difflib」モジュールとは
「difflib」は、シーケンスを比較するためのpython標準モジュールです。
シーケンスとは、順番に並んだ一続きのデータのことを指すので、順番を含めてファイルや文字列の中身を比較できると解釈できます。
なお、「difflib」は標準モジュールのため、インストールせずに使用することができます。(ただし、importは必要です)
「difflib」モジュールの3つのクラスについて
「difflib」モジュールには、3つのクラスが用意されています。
difflibモジュールの3つのクラス
・Differ
・HtmlDiff
・SequenceMatcher
【Differクラス】
文字列からなる2つのシーケンスを比較し、差分を生成します。
各シーケンスの要素としては、改行で終わる、単一行からなる文字列を与える必要があります。
例えば、ファイルオブジェクトのreadlinesメソッドを使うと、そのような単一行からなる文字列を生成できます。
【HtmlDiffクラス】
2つのテキストを左右に並べて比較表示し、行間や行内の変更点を強調表示するHtmlテーブルを生成します。
ファイルの差分を視覚的に理解しやすいクラスです。
【SequenceMatcherクラス】
もっとも柔軟性のあるクラスです。
シーケンスの類似度などを測定するratio関数なども使用できます。
スポンサーリンク
Differクラスでファイルの比較結果を出力する方法
はじめに、Differクラスのcompare関数で、2つのファイルの差分を出力する方法を紹介します。
以下、サンプルコードです。
### Differクラスでファイルを比較
import os
import difflib
dir_path = r'C:\ --- ファイルの保存先 --- \folder'
file1_name = 'file1.txt'
file2_name = 'file2.txt'
file1_path = os.path.join(dir_path, file1_name)
file2_path = os.path.join(dir_path, file2_name)
file1 = open(file1_path)
file2 = open(file2_path)
diff = difflib.Differ()
output_diff = diff.compare(file1.readlines(), file2.readlines())
print('\n'.join(output_diff))
file1.close()
file2.close()
"""
Apple
+ Orange
Banana
- Orange
Grape
- Lemon
+ Lemmon
? +
- Peach
Mango
"""出力結果のコードの見方について、pythonのライブラリリファレンスから引用しました。
引用:Pythonライブラリリファレンス

今回比較したファイルでは、Lemonと、そのスペルミスのLemmonを比較していますが、
行として異なると判断されており、スペルミスを指摘するような出力とはなっていません。
> diff = difflib.Differ()
Differオブジェクトを生成しています。
> output_diff = diff.compare(file1.readlines(), file2.readlines())
Differオブジェクトのcompareで、差分を生成しています。
compareの引数には、ファイルオブジェクトのreadlinesメソッドで単一行からなる文字列を渡しています。
【補足】ファイルの差分のみ抽出
先ほどのdifflibモジュールのDifferクラスの出力結果から、差分のみを抽出する方法を紹介します。
以下、サンプルコードです。
### Differクラスでファイルを比較し、差分のみ抽出
import os
import difflib
dir_path = r'C:\ --- ファイルの保存先 --- \folder'
file1_name = 'file1.txt'
file2_name = 'file2.txt'
file1_path = os.path.join(dir_path, file1_name)
file2_path = os.path.join(dir_path, file2_name)
file1 = open(file1_path)
file2 = open(file2_path)
diff = difflib.Differ()
output_diff = diff.compare(file1.readlines(), file2.readlines())
for data in output_diff :
if data[0:1] in ['+', '-'] :
print(data)
file1.close()
file2.close()
"""
+ Orange
- Orange
- Lemon
+ Lemmon
- Peach
"""> for data in output_diff :
差分の出力結果から1行ずつdataに渡しています。
> if data[0:1] in ['+', '-'] :
data[0:1]で、コード部分だけ抜き出し、それが"+" 、"-" と一致するか判定しています。
【補足】ファイルの一致箇所のみ抽出
difflibモジュールのDifferクラスの出力結果から、一致箇所のみを抽出する方法を紹介します。
先ほどのサンプルコードの ifの条件文 を書き換えるだけです。
### Differクラスでファイルを比較し、一致箇所のみ抽出
import os
import difflib
dir_path = r'C:\ --- ファイルの保存先 --- \folder'
file1_name = 'file1.txt'
file2_name = 'file2.txt'
file1_path = os.path.join(dir_path, file1_name)
file2_path = os.path.join(dir_path, file2_name)
file1 = open(file1_path)
file2 = open(file2_path)
diff = difflib.Differ()
output_diff = diff.compare(file1.readlines(), file2.readlines())
for data in output_diff :
if data[0:1] not in ['+', '-', '?'] :
print(data)
file1.close()
file2.close()
"""
Apple
Banana
Grape
Mango
"""スポンサーリンク
HtmlDiffクラスでファイルの比較結果を出力する方法
次に、HtmlDiffクラスでファイルの比較結果を出力する方法を紹介します。
以下、サンプルコードです。
### HtmlDiffクラスでファイルを比較
import os
import difflib
dir_path = r'C:\ --- ファイルの保存先 --- \folder'
file1_name = 'file1.txt'
file2_name = 'file2.txt'
file1_path = os.path.join(dir_path, file1_name)
file2_path = os.path.join(dir_path, file2_name)
file1 = open(file1_path)
file2 = open(file2_path)
diff = difflib.HtmlDiff()
output_name = 'diff.html'
output_path = os.path.join(dir_path, output_name)
output = open(output_path, 'w')
output.writelines(diff.make_file(file1, file2))
file1.close()
file2.close()
output.close()以下のファイル " diff.html " が出力されます。
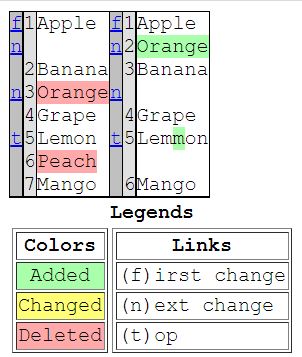
2つのテキストが左右に並べて比較表示されており、変更点が強調表示されているので視覚的にとても分かりやすいです。
Lemonのスペルミスも差分として抽出されています。
スポンサーリンク
SequenceMatcherクラスの使用例
次に、SequenceMatcherクラスの使用例を紹介します。
SequenceMatcherクラスにはいくつか関数がありますが、その中から、get_opcodesとratioの使用例を紹介します。
get_opcodesで、2つの文字列の差分を抽出
get_opcodesは、1つ目の文字列を2つ目の文字列にするための方法を、5つのタプルとして出力します。
以下、サンプルコードです。
### get_opcodesで、2つの文字列の差分を抽出
import difflib
fruits1 = 'Apple Banana Orange Peach Mango'
fruits2 = 'Apple Banana Peach Mango Orange Grape'
s = difflib.SequenceMatcher(None, fruits1, fruits2)
for tag, i1, i2, j1, j2 in s.get_opcodes() :
print('{:7} fruits1[{}:{}] --> fruits2[{}:{}] {!r:>8} --> {!r}'.format(
tag, i1, i2, j1, j2, fruits1[i1:i2], fruits2[j1:j2]))
"""
equal fruits1[0:13] --> fruits2[0:13] 'Apple Banana ' --> 'Apple Banana '
delete fruits1[13:20] --> fruits2[13:13] 'Orange ' --> ''
equal fruits1[20:31] --> fruits2[13:24] 'Peach Mango' --> 'Peach Mango'
insert fruits1[31:31] --> fruits2[24:37] '' --> ' Orange Grape'
"""get_opcodesの出力結果のtagの値の見方は、下記のとおりです。
Pythonライブラリリファレンスから引用しています。
引用:Pythonライブラリリファレンス

ratioで、2つの文字列の類似度を取得
ratioは、2つのシーケンスの類似度を出力します。
以下、サンプルコードです。
### ratioで、2つの文字列の類似度を算出
import difflib
fruits1 = 'Apple Banana Orange Peach Mango'
fruits2 = 'Apple Banana Peach Mango Orange Grape'
fruits3 = 'Apple Banana Orange Peach Grape'
s12 = difflib.SequenceMatcher(None, fruits1, fruits2)
print(s12.ratio())
# 0.7058823529411765
s13 = difflib.SequenceMatcher(None, fruits1, fruits3)
print(s13.ratio())
# 0.8709677419354839スポンサーリンク
まとめ
pythonにおいて、ファイルを比較し、差分や一致箇所を抽出する方法を紹介しました。
ファイル操作に関するライブラリやモジュールは知っておくと便利なものが多いので、自分の手を動かして習得し、自在に使いこなせるようにしておきましょう。
スポンサーリンク