pythonで、テキストファイルから、任意の文字列を検索し抽出する方法を紹介します。
また、補足的な内容ですが、テキストファイルの特定行を抽出する方法についても紹介します。
本記事では、以下の内容を紹介します。
この記事で分かること
■ファイル内の文字列を検索・抽出
- ファイル内の文字列を検索・抽出するサンプルコード
- ファイル内の文字列を検索し、行番号を取得する方法
【補足】ファイル内の行番号を指定して、特定行を抽出
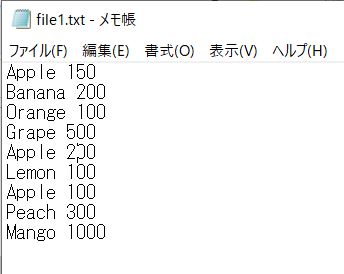
なお、本記事のサンプルコードでは、下記のテキストファイルを例として読み込んでいます。
スポンサーリンク
ファイル内の文字列を検索・抽出
テキストファイルを読み込み、文字列を検索・抽出する方法を紹介します。
はじめにサンプルコードを紹介し、各操作について解説します。
以下、テキストファイルから文字列を検索・抽出するサンプルコードです。
### ファイル内の文字列を検索・抽出
import os
dir_path = r'C:\ *--- 任意のディレクトリ ---* '
file_name = 'file1.txt'
file_path = os.path.join(dir_path, file_name)
with open(file_path) as f:
lines = f.readlines()
print(lines)
# ['Apple 150\n', 'Banana 200\n', 'Orange 100\n', 'Grape 500\n', 'Apple 200\n', 'Lemon 100\n', 'Apple 100\n', 'Peach 300\n', 'Mango 1000']
lines_strip = [line.strip() for line in lines ]
print(lines_strip)
# ['Apple 150', 'Banana 200', 'Orange 100', 'Grape 500', 'Apple 200', 'Lemon 100', 'Apple 100', 'Peach 300', 'Mango 1000']
list_Apple = [line_s for line_s in lines_strip if 'Apple' in line_s ]
print(list_Apple)
# ['Apple 150', 'Apple 200', 'Apple 100']
list_Apple_value = [item.split()[1] for item in list_Apple ]
print(list_Apple_value)
# ['150', '200', '100']> file_path = os.path.join(dir_path, file_name)
ディレクトリのパスと、ファイル名から、ファイルのパスを生成しています。
> with open(file_path) as f :
> lines = f.readlines( )
with構文でファイルを開いています。
with構文は、ファイルを使用後にファイルを閉じる処理も行ってくれるため、閉じ忘れによるエラーを回避することができます。
ファイルオブジェクトのreadlinesメソッドで、ファイルの中身を行ごとのリストとして取得しています。
> lines_strip = [ line.strip( ) for line in lines ]
readlinesメソッドでデータを取得した状態だと、要素の最後に改行コード「\n」がついてしまうため、
stripメソッドで改行コードを削除しています。
また、内包表記を用いることで、改行コードを削除した要素から新たなリストを生成しています。
内包表記については、下記の記事で紹介しています。
> list_Apple = [line_s for line_s in lines_strip if 'Apple' in line_s ]
リスト " lines_strip " の要素から、文字列"Apple"が含まれるものを抽出しています。
内包表記で、" lines_strip " の要素を1つずつ取り出し、変数 " line_s " に渡しています。
" if + 条件式 "で、変数 " line_s " に渡された要素について、文字列 "Apple" が含まれるか判定しています。
文字列 "Apple" が含まれる要素から、新たなリストを生成しています。
> list_Apple_value = [item.split( )[1] for item in list_Apple ]
文字列 "Apple" の後にある、値を取得しています。
内包表記で、リスト "list_Apple"の要素を1つずつ変数 "item" に渡しています。
itemに格納された値を、空白で区切るために、splitメソッドを使用しています。
"Apple"の後ろの値は、item.split( )[1] とすることで取得できます。
スポンサーリンク
ファイル内の文字列を検索し、行番号を取得
ファイル内の文字列検索の変形例として、検索した文字列を含む行の、行番号を取得する例を紹介します。
以下、サンプルコードです。
### ファイル内の文字列を検索し、行番号を取得
import os
dir_path = r'C:\ *--- 任意のディレクトリ ---* '
file_name = 'file1.txt'
file_path = os.path.join(dir_path, file_name)
with open(file_path) as f:
lines = f.readlines()
print(lines)
# ['Apple 150\n', 'Banana 200\n', 'Orange 100\n', 'Grape 500\n', 'Apple 200\n', 'Lemon 100\n', 'Apple 100\n', 'Peach 300\n', 'Mango 1000']
lines_strip = [line.strip() for line in lines ]
print(lines_strip)
# ['Apple 150', 'Banana 200', 'Orange 100', 'Grape 500', 'Apple 200', 'Lemon 100', 'Apple 100', 'Peach 300', 'Mango 1000']
list_rownum = [i for i, line_s in enumerate(lines_strip) if 'Apple' in line_s ]
print(list_rownum)
# [0, 4, 6]> list_rownum = [i for i, line_s in enumerate( lines_strip ) if 'Apple' in line_s ]
文字列を検索し、文字列を含む行の行番号を取得しています。
enumerate関数を用いることで、イテラブルオブジェクトの、インデックスと要素を同時に取得できます。
ここでは、インデックスを変数 i へ、要素を変数 line_s へそれぞれ渡しています。
if + 条件式で、文字列 "Apple" が、line_sに含まれるか判定し、Trueとなる変数 i から、新たなリストを生成します。
enumerate関数については、下記の記事で紹介しています。
スポンサーリンク
【補足】ファイル内の行番号を指定して、特定行を抽出
補足的な内容として、ファイル内の行番号を指定して、特定行を抽出する方法を紹介します。
以下、サンプルコードです。
readlinesメソッドでファイルを行ごとのリストとして取得したあとに、行番号を指定することで特定行を抽出できます。
スライスも使用できます。
### ファイルの行番号を指定して、特定行を抽出
import os
dir_path = r'C:\ *--- 任意のディレクトリ ---* '
file_name = 'file1.txt'
file_path = os.path.join(dir_path, file_name)
with open(file_path) as f:
lines = f.readlines()
print(lines[2])
# Orange 100
lines_strip = [ line.strip() for line in lines[2:5] ]
print(lines_strip)
# ['Orange 100', 'Grape 500', 'Apple 200']> lines_strip = [ line.strip() for line in lines[2:5] ]
スライスで複数行を指定しています。
リストの要素の最後に改行コードがついてしまうため、stripメソッドで改行コードを除去した後に、新たなリストを生成しています。
スポンサーリンク
まとめ
pythonで、テキストファイルから任意の文字列を検索し抽出する方法を紹介しました。
今回紹介したサンプルコードにも使用している、with構文やreadlinesメソッドは、ファイル操作では必須の内容なので、理解して使いこなせるようにしておきましょう。
スポンサーリンク